Interested in learning how to compare certain budgeted scenarios vs. actuals? In this blog post, I will demonstrate a technique to show you how to do that.
Continue readingYear 2020: Pandemic, Power BI, and Beyond…

There have been some amazing Power BI releases this year. I have compiled some of my favourite features that directly impacted how I used Power BI.
Continue readingHow to Create an Amazon-esque Shipping Status report in Power BI
In this blog post, I’m going to talk about how we can create a shipping status in Power BI that visually shows the selected order’s shipping status. This will have look and feel similar to shipping statuses on websites like Amazon, providing a clear way to see your order’s status visually!
Before we begin, let’s first understand the data. We have three tables in this model:
- Statuses
- Orders
- Order Statuses
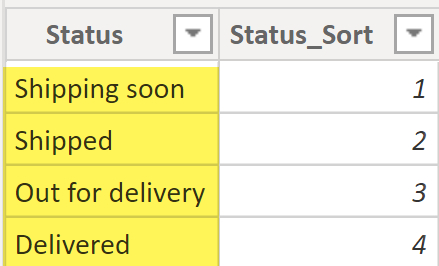
The Statuses table has a unique value for each shipping status and a status sort column. The status sort column is used to sort the shipping status by the shipping lifecycle (chronological order) rather than sorting the shipping statuses alphabetically. You can read more about “sort by” at this link.
In our example, we are assuming that each order goes through four shipping statuses, as per the sequence below:
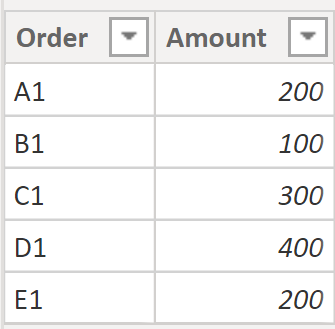
The next table is the Orders table, which is just simple a list of the orders and their respective order amounts. In our example, we have five orders as seen below.
The Order Status table contains the shipping status for each order. Each row represents the shipping status of a certain order at any given moment. This table will be the one driving the logic to use the Amazon-esque shipping status. Let’s have a quick look at the data in our Order Statuses table:
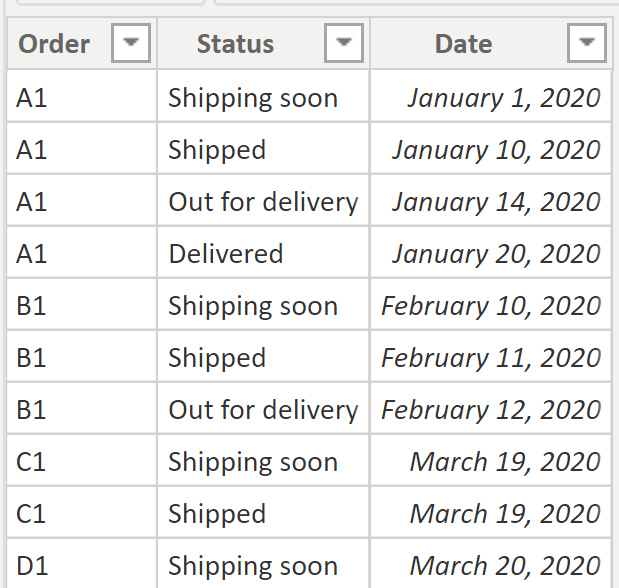
In the Order Status table, we are just storing the shipping value; in a real scenario, we would probably have a shipping status key, but that won’t have any impact on our final output here so we can skip it. If we had a shipping status key, the only that thing that would need to be changed would be to make the relationship between the Order Statuses and Statuses tables based on the shipping status key column.
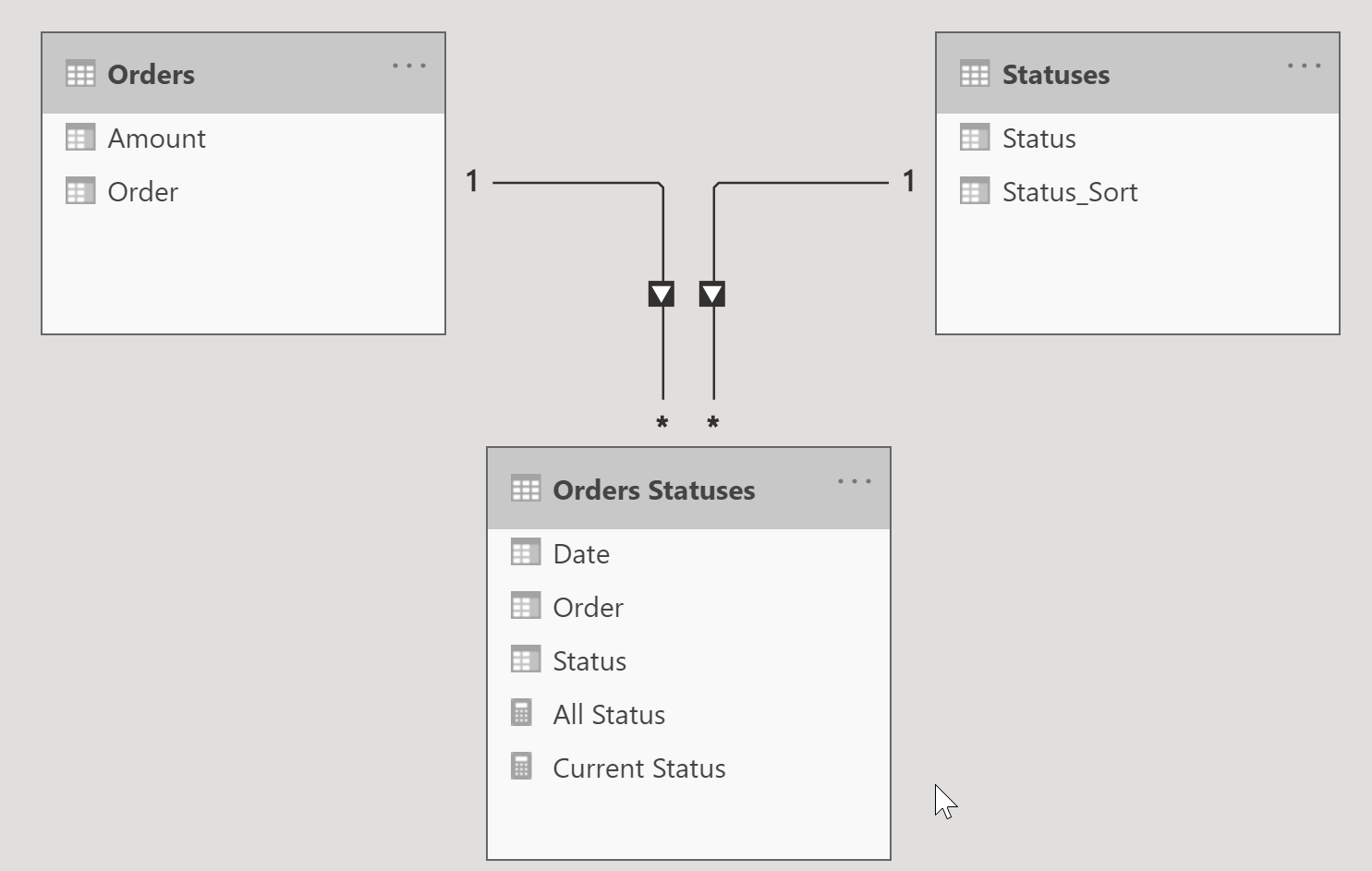
Let’s take a quick look at the relationship diagram for this model. It’s pretty straightforward: one order can have more than one shipping status and one status can have multiple orders.
Now that we have good understanding of our tables and their relationships, we can move into the fun part! To visualize the Amazon-esque shipping status, we will need to add two measures into our model. These simple measures will be used on a line chart visual in order to give us the look and feel we we want.
Measure 1: The Show Status measure will be used to show the grey line and circles for the shipping status. If an order is selected, the measure will return a fixed value of 1, otherwise it will return a blank value. This measure is essentially used to visualize the grey shipping status line and circles.
Show Status =
VAR _SelectedOrder = SELECTEDVALUE ( 'Orders'[Order] )
RETURN
IF ( NOT ISBLANK ( _SelectedOrder ),
1
)Measure 2: The following Highlight Status measure will return a fixed value of 1 based on each shipping status of the order, which is in turn based on the current row context of the status from the Statuses table. This measure is essentially used to visualize the highlighting of the shipping status line and circles depending on where to the order is in the shipping status timeline.
Highlight Status =
VAR _SelectedOrder = SELECTEDVALUE ( 'Orders'[Order] )
VAR _orderStatus =
IF ( NOT ISBLANK ( _SelectedOrder ),
//find out if current selected order has row(s) filtered on status in the current row context
CALCULATE (
COUNTROWS ( 'Orders Statuses' ),
TREATAS(
VALUES ( 'Statuses'[Status] ),
'Orders Statuses'[Status]
)
)
)
RETURN
--if no row found then return blank else return 1 to highlight the status in the visual
IF ( NOT ISBLANK ( _orderStatus ), 1 ) Now let’s put everything together. Create a tooltip page with a line chart that will be used to show the shipping status of the order. To learn more about how to create a report tooltip page, refer to this link.
Here are the steps to create a tooltip page:
- Under page information, turn on Tooltip.
- Set the page size to a custom size of 414×120.
- Add a line chart visual.
- On the x-axis, add the Status column from the Statuses table.
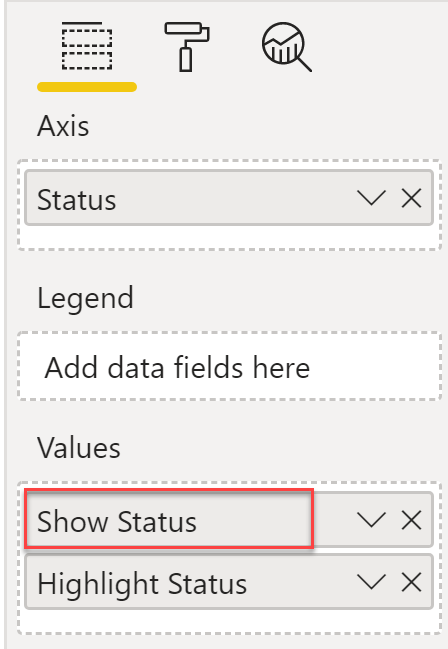
- Under values, add the Show Status and Highlight Status measures.
🤚
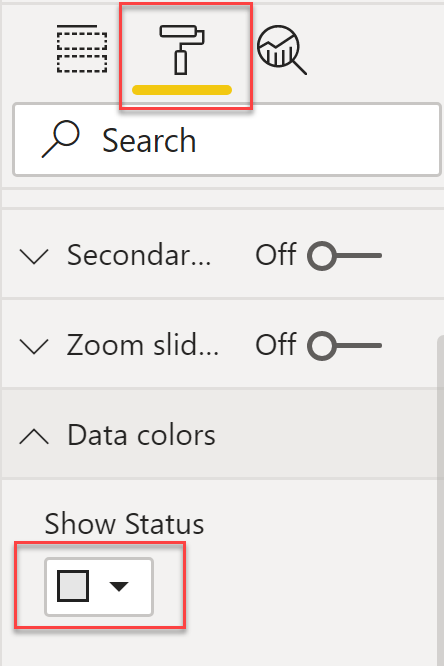
The sequence of these measures in the values section of the line chart is very important. Make sure that the first measure in the values section is Show Status. Also, on the formatting pane, change the data colour for this measure to grey.
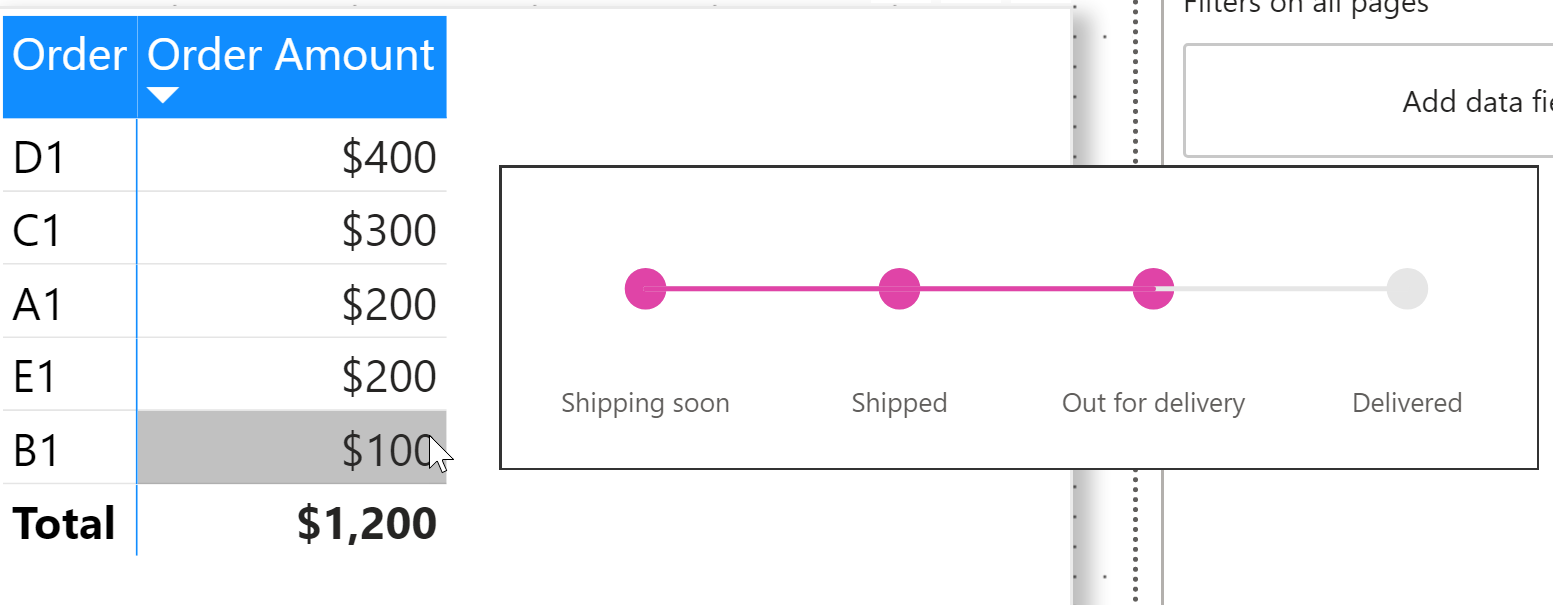
I then added a page that has two visuals – a bar chart and a matrix, as you can see in the video – and assigned the previously created report tooltip page as the tooltip for these visuals. Voila – as we hover over a data point in our visuals, we can see the highlighted shipping status of the order!
👉 Make sure to subscribe to our blog post. In the near future, I will create something similar given we don’t have a separate table for order statuses but only the most recent shipping status available for an order.
How to show the sum of non-selected categories grouped together as "Other" category in visuals

I recently came across an interesting problem regarding how you can show the sum of values of certain selected categories as separate bars in a bar chart – but with the sum of all the non-selected categories being grouped together in an “Other” category/bar. If you take a look at the above video, you can see that as I select various categories the value for the “Other” bar is changing (the last bar). It also shows you the difference between the Total Sales and all the selected categories. If all the categories are selected (or no category is selected), then the “Other” bar disappears from the visual.
The particular business use case is that when there are too many categories, visuals can get very cluttered. I wanted to come up with a solution for this problem and I came up with this method to show only selected categories as individual bars with the rest of categories summed together in a separate – “Other” – bar in the visual. This method isn’t only applicable to bar charts – you can use it in any visual!
Let’s first look at our sample data and then the solution. The following sample data contains only three columns: Category, Sales, and Category Sort. The Category Sort column is used to sort by column for the Category column .

First and foremost part of the solution is to create a table with distinct Category values and add a record with Other as category value and this will be used to show sum of all non-selected categories, See screen shot below. I gave the sort order value for Other row to 999999, big enough number that it shows up at as the last value in the visuals, if we want Other to be the first row in the visual, I will set the Category Sort value to like negative 1 (-1).

Make sure this Category table doesn’t have relationship with your main data table.
I added following measures to make the calculation work, I created multiple measures but all this can be collapsed into one, my performance preference is to create separate measures, so that measures can be recycled where possible.
Sum Sales is a base measure.
Sum Sales = SUM ( Data[Sales] )
Sum All is a measure used to get us Total Sales regardless of selection of Categories.
Sum All = CALCULATE ( [Sum Sales], ALL ( Data[Category] ) )
Sum Others is a measure to show what value we have for non-selected categories, in other case, what value we will see in Other category when we will visualize our data.
Sum Others = [Sum All] - [Sum Sales]
Sum Sales and Others is the core measure which we will use in the visual, I have added the comments in the measure to explain what each row in the measure is used for.
Sum Sales and Others =
VAR __valueOther = "Other" --variable to store the value for "Other" so that we have it at one place to use in the DAX
VAR __selectedCategory = --create a table of selected categories and append "Other" as an extra row
UNION (
VALUES ( Data[Category] ),
{ __valueOther }
)
RETURN
IF ( MAX ( Category[Category] ) = __valueOther, --check if current value is "Other"
IF ( [Sum Others] > 0, [Sum Others] ), --if condition to suppress other value in case all the categories are selected,
CALCULATE (
[Sum Sales],
//TREATUS is used to filter data table
TREATAS (
INTERSECT ( VALUES ( Category[Category] ), __selectedCategory ), --get list of categories that are selected
Data[Category]
)
)
)
In above measure, if want to show 0 value for Other if all the categories are selected then remove IF condition line in the measure and just simply use Sum Others measure.
Since we have all our measures in places, we will visualize the data. Let’s add a slicer for Category and make sure the Category column in this case is used from your Data Table not from Category Table.
Add a Stacked Column Chart or any other visual you would like to see. On X-Axis, put Category from Category Table and put Sum Sales and Others measure in Values section.

👉 Make sure on X-Axis, put Category from Category Table, not from Data Table.
and that’s it, as you can see at the start of the post, Other bar value will change based on the selected categories. I hope you can leverage this technique to meet your business needs. Let me know what you think. Share your thoughts.
Create a basic Date table in your data model for Time Intelligence calculations

In this blog post, I am going to show you how you can quickly add a very basic Date table to your model. You might be wondering – why do you need a Date table? A Date table is very important to be able to use Time Intelligence DAX functions such as year to date, month to date, quarter to date, same period last year, parallel period, and many other similar calculations that are based on the time/period. There are approximately 35 built-in time intelligence DAX functions and we can leverage them by adding a Date table to our model.
The basic feature of the Date table is that you need continuous dates in your table. There is only unique date value, and on top of it you can add other columns, like Year, Month, Weekday, etc. based on your requirements of how you want to slice and dice the data. Some people may have a requirement to slice the data by Week Number (of the year) and others might not need this column as they would never use it.
From my experience, I have found that the following are key columns to include in your Date table. These are used quite frequently:
- Date (this is the basic feature in the Date table, both the continuous date and unique values)
- Year
- Quarter
- Month Name
- Month Number
- Month Year
So, what should the start and end date be in the Date table? Usually, you want to create a Date table from the start of the year (January 1st) , based on first date in your fact table. For example, if your first sale is on February 15, 2019 in your fact table then your Date table should start from January 1, 2019. The last date should be at least December 31 of the current year and if you have future date transactions in your model then the last date should be based on last date in your transaction table. Let’s assume that you have a transaction table which has future date transactions – let’s say some in 2021 and some in 2022. In this case, our last date for our Date table will be December 31, 2022. There is no problem with having dates in the future.
Let’s look at some examples of what the date range would be in the Date table at the time of writing this post (May 20th, 2020):
| Earliest date in transaction table | Last date in transaction table | Date ranges for Date table |
|---|---|---|
| February 15, 2018 | January 5, 2019 | January 1, 2018 – December 31, 2020 |
| June 20, 2019 | May 31, 2021 | January 1, 2019 – December 31, 2021 |
| January 13, 2020 | December 31, 2023 | January 1, 2020 – December 31, 2023 |
Now, how do we create a Date table? We have two DAX functions available to create this table: CALENDAR and CALENDARAUTO. The main difference between these two function is that you pass the date range to the CALENDAR function whereas the CALENDARAUTO function looks at your data model and creates a date range based on the minimum and maximum date available in the model. The latter is exactly what we’re looking for.
Assume that I have a Sales table in my model and that the first sales date is on April 3rd, 2017. There is also a future sales date on November 30, 2022. We will use the CALENDARAUTO function to create a Date table and add other basic columns like Year, Month, Quarter etc.
Click the Calculated Table icon in the Modelling tab to add the DAX expression to create a Date table.

Simply copy the below code to create the Date table in your model
Date =
//start date in my case I'm setting to 2010
//you can get date from your transaction table and start from that year, something like this
//in __startDate replace DATE (2010, 1, 1 )
//with -> DATE ( YEAR ( MIN ( YourTransactionTable[DateColumn] ) ), 1, 1 )
VAR __startDate = DATE ( 2010, 1, 1 )
VAR __endDate = DATE ( YEAR ( TODAY() ), 12, 31 )
VAR __dates = CALENDAR ( __startDate, __endDate )
RETURN
ADDCOLUMNS (
__dates,
"Year", YEAR ( [Date] ),
"Month Number", MONTH ( [Date] ),
"Month Name", FORMAT ( [Date], "MMMM" ), --use MMMM for full month name, January instead of Jan
"Month", FORMAT( [Date], "MMM, YYYY" ), --use MMMMM for full month name, January instead of Ja
"Month Sort", FORMAT( [Date], "YYYY-MM" ),
"Quarter", "Q" & FORMAT( [Date], "Q, YYYY" ),
"Quarter Sort", FORMAT ( [Date], "YYYY-Q" )
)With the above DAX expression, we get a Date table with the following columns:

Now let’s check the date range we have in our Date table against what we have in our Sales table. I created MIN and MAX measures on the Date columns from both tables and depicted the results in the visual below. We can clearly see that our Date table has a date range from January 1, 2017 to December 31, 2022 and that the first date of sale is April 3, 2017 and the last date of sale is November 30th, 2022. The date range in our Date table clearly aligns with this.

Another good feature of using the CALENDARAUTO function is that we don’t need to worry about changing the date range. As new data comes in when we refresh our Sales table, the date range for the Date table will automatically grow based on the dates in the Sales table.
One important aspect after we create the Date table is to mark this as a “Date Table.” I don’t want to go into too much detail about this, but you can read all about it here. Once we have marked our Date table, we are going to set the sorting of our columns so that when we visualize our data, our values show up correctly. For example, if we don’t sort our Month Name column then everywhere we use Month Name it will be sorted alphabetically. This means that April will shows up as the first month instead of January. I also want to hide any unwanted columns – in this case I’m going to hide the Month Sort and Quarter Sort columns because they are only used for sorting purposes but are never going to be directly used in the visualization.
You can read more about sort by column here.
The following table lists all the columns that we are going to sort and what columns we are going to sort them by.
| Column Name | Sort by Column Name |
|---|---|
| Month Name | Month Number |
| Month | Month Sort |
| Quarter | Quarter Sort |
Something else I always do is change the aggregation method of any number columns to “Don’t Aggregate.” In our case, Year and Month Number are showing as aggregated columns and we know that we will never have a Sum of the Year column or the Month Number column.

One last thing – make sure you create a relationship between the Date column from your other tables to the Date table. In this case, the Date column from the Sales table to the Date column from the Date table. Now you can use the new Date table for all your Time Intelligence measures!
As best practice, always add a Date table in your model
Illuminate KPI cards with new shadow feature and conditional formatting

The May 2020 Power BI update (which was released today, May 19th, 2020) has a new feature that allows you to set a shadow around your visuals. I had a little bit of fun testing out this feature; I used it to to illuminate KPI cards with conditional formatting to tell a more interesting story.
To illustrate this new feature, I just created a simple Sales vs Sales Target KPI card, as you can see above.
I created a what-if parameter to set the Sales Target value and then calculated % Sales against this Target value. I then created another simple measure to set the shadow colour based on % Sales Target achieved. I used conditional formatting to change the shadow according to the following parameters:
- If the % Sales vs Target is more than 90%, then Green,
- If the % Sales vs Target is more than 70% but less than 90%, then Yellow,
- otherwise Red.
Add following measures (I called it Shadow Color) for conditional formatting and this measure we will use to illuminate KPI card
Sales Status =
VAR __targetAchieved = [% Target Achieved] --simple measure to calculate % of target achieved dividing sales by target
RETURN
SWITCH (
TRUE(),
__targetAchieved > .9, 1, --above 90%
__targetAchieved > .7, 2, -- above 70%
3
)
Shadow Color =
VAR __salesStatus = [Sales Status]
RETURN
SWITCH (
__salesStatus,
1, "#7FC600",
2, "#F9C700",
"#C6001C"
)
Let’s add above measure to set the shadow for the KPI Card. Follow steps in next image for conditional formatting:
- Click fx button to set conditional formatting
- Select Field Value in Format by drop down
- Under Based on field choose the measure name, in this case it is called Shadow Color

Finally, make tweak to shadow settings by selecting Custom value in Preset section so that shadow show up around KPI card

And that’s it! You can highlight visuals using this new shadow feature, along with conditional formatting, to create stunning reports. For an example of what the finished product looks like, please see the image at the beginning of this post.
I hope you find this new feature useful and are able to use it to tell a data story within your organization.
Useful Links
Read more about conditional formatting here.
Read more about the new shadow feature here.
Transform Data in Power Query using the Unpivot and Pivot Functions

As you know, we can get data in all forms and shapes and sometime it’s simply NOT possible to use the data directly as we receive it. In these cases, Power Query comes to our rescue to help us shape and transform data so that we can use it in our reports.
I recently came across a question on the Power BI community forum where data was available in the following shape with Product, Kg and Bag columns for each Customer and each Date.
Before Transformation

Given the above data, it’s not possible to create reports where you can slice the data by product, compare customer sales by product, or perform any other type of analysis. The ideal shape and form of the above data should be as depicted below – do you guys agree? This form of data allows us to have a 360-degree view with the ability to slice by products and compare various data elements.
After Transformation

It was really easy to transform the data using the Unpivot and Pivot transformation functions in Power Query. See the Power Query script and steps below that transformed the data into its required shape.
Power Query Script
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WMtQ31DcyMLRU0lFyBOKgzORUIGVoACKAOCC/JLEkHyxiABGP1QFpMkLWBFdkBFJjhDDGCKzJCKbJGKbJCYhD8nMTi8C6jEGKjEHCqYl5xWABA4gwRJsJTJszkhoTkBITFAEDiHBsLAA=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type text) meta [Serialized.Text = true]) in type table [Date = _t, Customer = _t, #"Prod 1" = _t, #"Kg 1" = _t, #"Bag 1" = _t, #"Prod 2" = _t, #"Kg 2" = _t, #"Bag 2" = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Date", type date}, {"Customer", type text}, {"Prod 1", type text}, {"Kg 1", Int64.Type}, {"Bag 1", Int64.Type}, {"Prod 2", type text}, {"Kg 2", Int64.Type}, {"Bag 2", Int64.Type}}),
#"Unpivoted except Date and Customer" = Table.UnpivotOtherColumns(#"Changed Type", {"Date", "Customer"}, "Attribute", "Value"),
#"Extracted Product" = Table.AddColumn(#"Unpivoted except Date and Customer", "Product", each if Text.Start([Attribute], 4)= "Prod" then [Value] else null, type text),
#"Filled Product" = Table.FillDown(#"Extracted Product",{"Product"}),
#"Added Unit Type Column" = Table.AddColumn(#"Filled Product", "Type", each Text.BeforeDelimiter([Attribute], " ")),
#"Filtered Value Rows Contains Product" = Table.SelectRows(#"Added Unit Type Column", each ([Product] <> [Value])),
#"Removed Attribute Columns" = Table.RemoveColumns(#"Filtered Value Rows Contains Product",{"Attribute"}),
#"Pivoted Column" = Table.Pivot(#"Removed Attribute Columns", List.Distinct(#"Removed Attribute Columns"[Type]), "Type", "Value", List.Sum),
#"Changed Data Type" = Table.TransformColumnTypes(#"Pivoted Column",{{"Kg", type number}, {"Bag", type number}})
in
#"Changed Data Type"
Key steps in above scripts are
- Unpivoted data for each date and customer (step #3)
- Added new Product column from Value column (step #4)
- Filled Product column (step #5)
- Added Unit Type column (step #6)
- Removed Product from Value column (Step #7)
- Pivoted on Unit Type column (step #9)
Caution: Pivot is an expensive transformation and it may not perform very well on a large dataset.
Relative date filtering and delayed month-end

Relative date filtering is a great way to filter your data while keeping the current date in context. I’m sure you may have used this feature many times before and find it very valuable – but it doesn’t always meet business requirements, especially when the relative date filtering is based on when the previous month-end process is completed. We usually see this in the Finance department when they close the books for the previous month in the subsequent month. This can take 3-5 business days – and in some cases, even more time.
Learn more about relative date filtering here.
In this blog post, I’m going to talk about how to work with relative date filtering based on when the month end-process is completed. For example, imagine a simple bar graph showing the last 12 months of sales data. In this bar graph, we are using relative date filtering, meaning that when we are in January 2020, the bar graph shows sales from January 2019 to December 2019. If we are in February 2020, sales are shown from February 2019 to January 2020 – so based on the current month, the last 12 months are always being shown. This can easily be achieved by using the in-built relative date filtering functionality. This is an awesome feature, but unfortunately it doesn’t work when we have to use relative date filtering based on when the month-end processing is completed.
Here is a problem statement posted on the Power BI Community forum:
I am a big fan of the Relative Date Slicer in Power BI. Financially – we report monthly. The majority of my reports use a Last 36 Months (Calendar) – and this works great. As I write this – my slice is 3/1/2016 – 2/28/2019. Just what I want.
My problem is – that window will change with the calendar. On the first of April – the dates the slicer uses will be 4/1/2016 – 3/31/2019. We have a processing cycle that takes about three or four business days to complete. So the calendar may say it is April – but that does not imply we are done with March. We typically are not ready for this switch until the 6th or 7th.
I can write a DAX function that would know the last certified date. I can also put a certified attribute on my Date dimension.
Does anyone have any ideas on how I can delay the transition?
In the above post, the certified date is a trigger that tells us when the previous month-end processing has been completed; this will help us calculate relative date filtering for our visuals.
Now let’s talk about how I approached this solution. The first thing to understand is how critical the Calendar table is for our solution. As a best practice, one must always have a Calendar table in their data model.
There are some great resources out there that talk about how to add a Calendar table to your model. I’m not going to discuss it here, but it is a very important part of our solution.
Here is what our sample data looks like:

There is also a Month End table which has a single Date column. This has a record for each month when the month-end processing is completed.
To calculate our relative date filtering, we are going to add a column to our Calendar table which we will call Month Offset. If the Month Offset value is 0, then that is the most recent month based on the most recent processing date. Negative values mean past months and positive values mean future months.
Month Offset =
VAR __monthEndDate = MAX( 'Month End'[Date] ) --get most recent processing date
VAR __date = IF( ISBLANK( __monthEndDate ), TODAY(), __monthEndDate ) --if there is no date then we use today's date
RETURN
DATEDIFF ( __date, 'Calendar'[Date], MONTH ) --calculate the offset value
Assuming the most recent month-end processing date is December 2019, then our Month Offset data will look like this:

To showcase this functionality, I created a power query parameter to change the most recent month-end processing date. In the video below, you can see how the bar graph changes based on this date:

Learn more about power query parameters here.
I have been able to use this technique to meet various financial reporting needs – what are some other techniques that you enjoy using?
Dynamic title/measure based on what is NOT chosen in a #powerbi Slicer

A few months ago, a very interesting question was posted on the Power BI community forum and I had the opportunity to work on it. Finally, I have the time to write a blog post about this so that we can all learn from it!
Before we start, here is the question that was asked:
“I’ve seen several posts on how to display the values chosen in a slicer… but what about displaying the values that weren’t chosen (de-selected) – i.e. “All Choices Except _____” My problem is that I have some slicers with 20+ choices in them, and they need to be able to multi-select. I could create a (verrrrry loooong) title that lists everything that was chosen, but even if you make the display big enough to see all of them, the really crucial piece of information is still obscured – namely, what was intentionally left out.
Example – you have a chart that displays the age demographics of people who eat fruit. There are only 5 age groups displayed in the graph, but there are potentially 25 different types of fruits. The fruits are in a slicer. Lets say you want to see the graph with all fruits except Grapefruits. So you go to your slicer select all choices and then de-select Grapefruit.
The normal dynamic slicer using CONCATENATEX is going to display the 24 fruits chosen, but unless you knew all 25 choices off the top of your head, you won’t notice that the one that’s missing is Grapefruit. So I’d like a measure capable of showing both the normal list of what was chosen in the slicer, BUT… if the number of choices selected is (TotalChoices – 1), then show “All Except ” and the one choice that was excluded. Even better, if I could allow 2 choices for the exclusion logic (“All Except Grapefruit, Raspberry”).
Is there a way to identify choices that have been de-selected? Any alternative ideas for ways to approach this?”
The sample data is just a list of Fruits and Vendor:

The request in the original post is to show list of not selected fruits (All except) if the total selected fruits are less than 1 or 2 of total available fruits. In other words, if 10 fruit values are available in the slicer, and let’s say the user selects 8 fruits then you want to show “All Except” – otherwise you want to show all the selected fruits. I made this option a bit more dynamic using a what-if parameter with the range from 0% – 100%, where you can set after what % you show not selected fruits (All except) – otherwise “selected” fruits are shown. Taking the previous example, if we have 10 fruit values available in the slicer, and the what-if parameter value is set to 90% this means that after 9 fruits are selected we show “All Except”. In case the what-if value is 80%, we show “All Except” after 8 values are selected and so on…
Here is a measure to achieve all this:
Slicer Values Selected =
VAR __selectedValues = VALUES ( Fruits[Fruit] )
VAR __totalValues = CALCULATETABLE ( VALUES ( Fruits[Fruit] ), ALL ( Fruits[Fruit] ) )
VAR __totalRows = COUNTROWS ( __totalValues )
VAR __selectedRows = COUNTROWS ( __selectedValues )
VAR __differenceRows = __totalRows - __selectedRows
VAR __perecentageSelected = DIVIDE ( __selectedRows, __totalRows )
RETURN
SWITCH( TRUE(),
__totalRows = __selectedRows || __selectedRows == BLANK(), "All values selected",
__perecentageSelected <= [Maximum Selected Value], CONCATENATEX( __selectedValues, Fruits[Fruit], ", " ),
"Selected except " & CONCATENATEX( EXCEPT ( __totalValues, __selectedValues ), Fruits[Fruit], ", " )
)
And here is the breakup of the above measure:
__selectedValues = Create a table of selected fruits
__totalValues = Create a table of all the possible fruits available
__totalRows = Count of total fruits table
__selectedRows = Count of total fruits selected
__differeceRows = total rows – selected rows
__percentageSelected = What is the % of selected fruits after which we want to show “All except”
In the final return (switch) statement we are checking :
- If the total and selected rows are equal, or if no rows are selected then “All values are selected.”
- If the percentage of selected values are less than or equal to the what-if parameter percentage values, then we show all selected values.
- Otherwise, just show “All Except.” In other words, don’t show the selected values.
Hope you find this post useful and can use this technique to provide valuable information to the report users.
Useful Links
Learn more about CONCATENATEX function here.
Restrict number of data points in Power BI visuals

Sometimes we have data for many years in our dataset, but we want to restrict how many data points we want to show in #powerbi visuals at any given point. In this blog post, I talk about how you can easily achieve this with a few #dax measures!
Continue reading